

Project description: Merging writing process data with lexica
During the last 20 years writing research2 has focused explicitly on the analysis of writing processes. More recently, logging programs (like Inputlog) enabled research2ers to record process data (e.g. keystrokes & pauses) in much more detail without interfering the cognitive activities.
In the current project we aggregate the logged process data from the letter level (keystroke) to the word level by merging them with lexica and Naturally Language Processing tools. This creates a very valuable basis for more linguistically oriented writing process research2.
Goal
Three steps
- aggregate letter to word level
- parsing the S-notation
- enriching process data with linguistic information
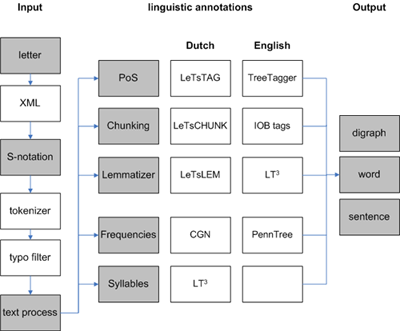
- part-of-speech tags,
- lemmas,
- chunks,
- syllable boundaries
- and word frequencies.
Funding
Budget: 27 000 euro.
Period
Promotor:
Co-promotors:
Read more
Leijten, M., Macken, L., Hoste, V., Van Horenbeeck, E., & Van Waes, L. (2012). From Character to Word Level:
Enabling the Linguistic Analyses of Inputlog Process Data M. Piotrowski, C. Mahlow & R. Dale (Eds.), European Association
for Computational Linguistics, EACL - Computational Linguistics and Writing (CL&W 2012): Linguistic and Cognitive Aspects of
Document Creation and Document Engineering (pp. 1-8).
View pdf
Macken, L., Hoste, V., Leijten, M., & Van Waes, L.(2012). From keystrokes to annotated process data: Enriching the output
of Inputlog with linguistic information. In N. Calzolari et al. (Eds.), Proceedings of the Eight International Conference on
Language Resources and Evaluation (LREC'12), pp. 2224-2229. European Language Resources Association (ELRA): Istanbul, Turkey
[ISBN: 978-2-9517408-7-7]
View pdf